
更新,爬虫贴出来了,试爬取了前100页列表的1000个资源,结果见帖中附件:
https://bbs.snow-plus.net/u.php?action-topic-uid-1156494.html
https://www.flhk.xyz/
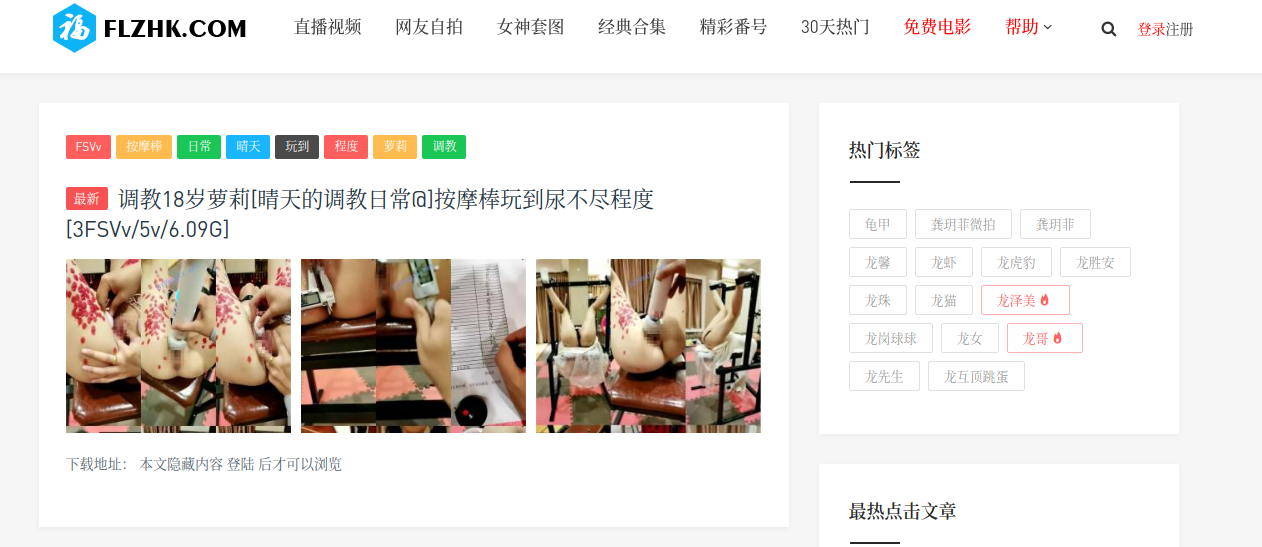
偶然发现这个福利网站的的资源下载链接存在于HTML源码中,只不过页面没有显示出来:
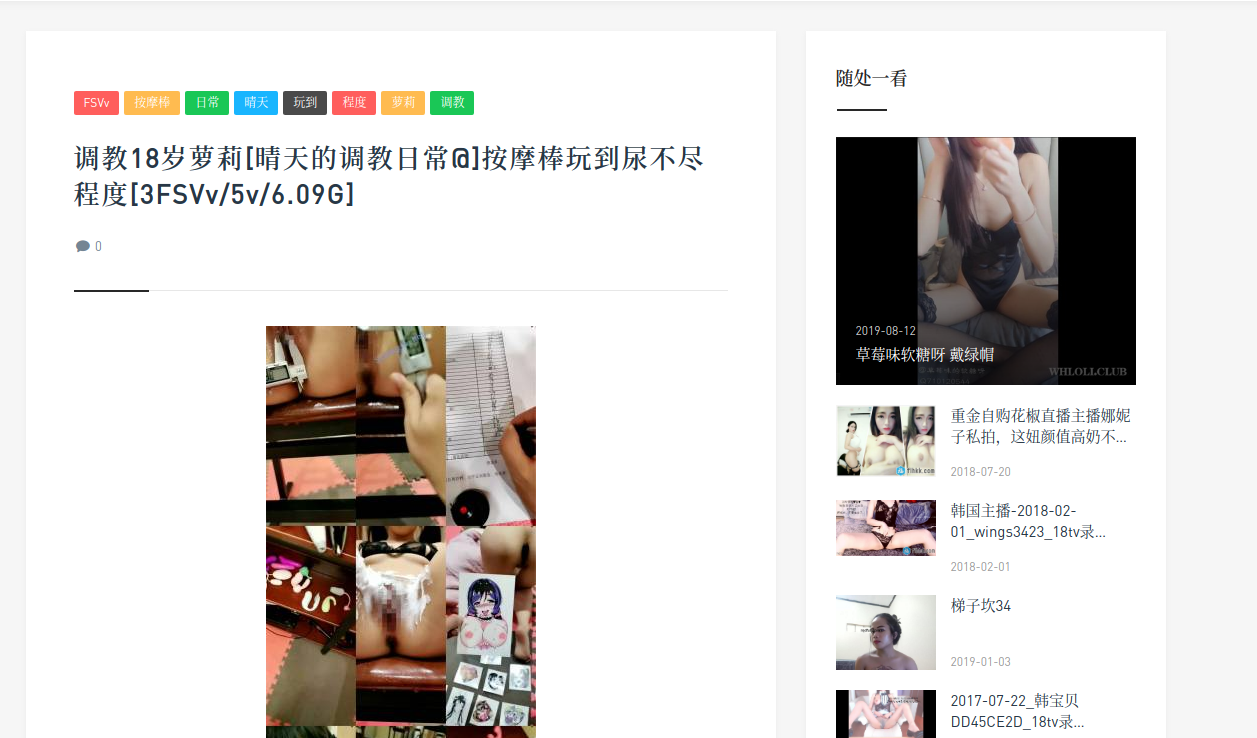
这里点击CTRL + U打开页面源码,可以看到在<meta>标签里有下载链接和解压密码:

下面这一行:
这个站的资源还挺多的,如果哪位想的话,写个简单的爬虫就可以把整个站的资源都抓下来,不知道这个漏洞能用多久,毕竟挺低级的,估计站长不太懂技术,一键搭建WordPress网站。
各位抓紧了
更新爬虫,有兴趣老哥可以尝试爬取资源,测试爬取5页所有资源用时14秒。
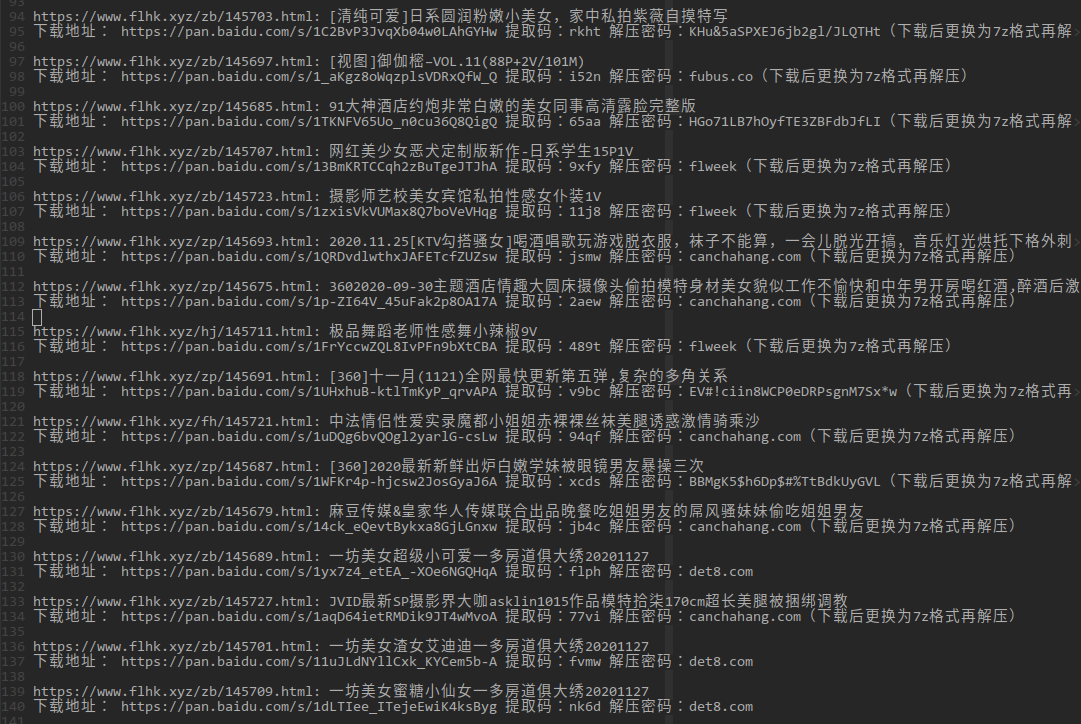
结果示意:
最后安利一下 (更新2020/11/28) 自己写的直播录制工具(支持斗鱼,b站, 虎牙), 可抓取显示弹幕
https://bbs.snow-plus.net/read.php?tid-1017998.html
欢迎各位测试
https://bbs.snow-plus.net/u.php?action-topic-uid-1156494.html
https://www.flhk.xyz/
偶然发现这个福利网站的的资源下载链接存在于HTML源码中,只不过页面没有显示出来:
这里点击CTRL + U打开页面源码,可以看到在<meta>标签里有下载链接和解压密码:
下面这一行:
复制代码
|
这个站的资源还挺多的,如果哪位想的话,写个简单的爬虫就可以把整个站的资源都抓下来,不知道这个漏洞能用多久,毕竟挺低级的,估计站长不太懂技术,一键搭建WordPress网站。
各位抓紧了
更新爬虫,有兴趣老哥可以尝试爬取资源,测试爬取5页所有资源用时14秒。
复制代码
|
结果示意:
最后安利一下 (更新2020/11/28) 自己写的直播录制工具(支持斗鱼,b站, 虎牙), 可抓取显示弹幕
https://bbs.snow-plus.net/read.php?tid-1017998.html
欢迎各位测试






